Inférence multivariée
Deux paramètres: cas général
Posterior \(\propto\) vraisemblance \(\times\) prior \(\Leftrightarrow p(\Theta|y) \propto \mathcal{L}_n \cdot p(\Theta)\)
Si \(\Theta = (\theta_1, \theta_2)\)
La vraisemblance est sans problème (aucun changement sur son expression)
Loi a priori \(p(\theta_1, \theta_2)\) → quelle distribution?
Prior conjoint: \(p(\theta_1, \theta_2)\)
Indépendance: \(p(\theta_1, \theta_2) = p(\theta_1) \cdot p(\theta_2)\) → deux cas univariés
Théorème de Bayes: \(p(\theta_1, \theta_2) = p(\theta_1 | \theta_2) \cdot p(\theta_2)\)
\(p(\theta_1 | \theta_2)\) : probabilité conditionnelle
\(p(\theta_2)\) : cas univarié
Loi a posteriori \(p(\theta_1, \theta_2 | y)\) → elle nous intéresse ainsi ?
Oui, si prior conjoint : \(p(\theta_1, \theta_2)\)
Connaissance et intérêt pour \((\theta_1, \theta_2)\)
Si non, on s'intéresse aux probabilités marginales: \(p(\theta_1 | y)\) et \(p(\theta_2 | y)\)
Solution: propriété \(p(x) = \int{p(x,y) \mathrm{d}y}\)
\(p(\theta_1 | y) = \displaystyle{\int}{p(\theta_1, \theta_2 | y) \mathrm{d} \theta_2}\)
\(p(\theta_2 | y) = \displaystyle{\int}{p(\theta_1, \theta_2 | y) \mathrm{d} \theta_1}\)
Bibliographie :
Plusieurs ouvrages proches
Différences sur notation et utilisation \(\Gamma \Leftrightarrow \mathsf{scaled-}\chi^2\)
Gelman A, Carlin JB, Stern AS, Rubin DB. Bayesian data analysis. Chapman \& Hall/CRC, 2004.
Hoff P. A first course in Bayesian statistical methods. Springer 2009.
Christensen R, Johson W, Branscum A, Hanson TE. Bayesian ideas and data analysis: an introduction for scientists and statisticians. CRC Press, 2011.
Lesaffre E, Lawson AB. Bayesian biostatistics Wiley, 2012.
Cowles MK. Applied Bayesian statistics - With R and OpenBUGS examples Springer, 2013.
Marin JM, Robert CP. Bayesian Essentials with R, Second Edition, Springer, 2014.
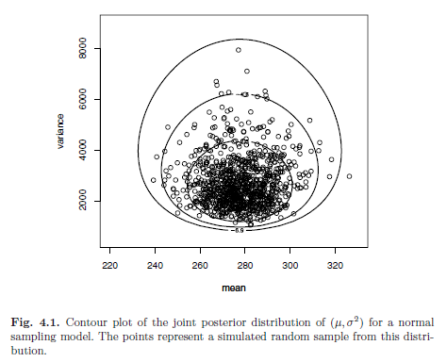
Deux paramètres : la normale
\(\Theta = (\mu, \sigma^2) \Rightarrow p(\mu, \sigma^2|y) \propto \mathcal{L}_n \cdot \color{blue}{p(\mu,\sigma^2)}\)
Prior conjoint: \(p(\mu,\sigma^2) \rightarrow\) (cf. page suivante)
Indépendance: \(p(\mu) p(\sigma^2) \rightarrow\) (cf. page suivante)
Conditionnement: \(p(\mu | \sigma^2) p(\sigma^2)\)
\(p(\mu | \sigma^2)\) : cas où la variance est connue
\(p(\sigma^2)\)
\(p(\sigma^2) \propto \mathsf{Cste}\) : cas où la variance est connue
\(p(\sigma^2) \rightarrow\) (cf. plus loin)
Conditionnement : \(p(\sigma^2 | \mu) p(\mu) \rightarrow\) rien de bien sympa !
(pas de forme analytique pour les lois a posteriori)